deepmind终结大模子幻觉?标注终究比人类靠谱、还省钱20倍,全开源
DeepMind 这篇论文一出,人类标注者的饭碗也要被砸了吗?
大模型的幻觉终于要终结了?
今日,社媒平台 reddit 上的一则帖子引起网友热议。帖子讨论(Discuss)的是谷歌 DeepMind 昨日提交的一篇论文《Long-form factuality in large language models》(大语言模型的长篇事实性),文中提出的方法和结果(Result)让人得出大胆的结论:对于负担得起的人来说,大语言模型幻觉不再是问题了。

我们(We)知道,大语言模型在响应开放式主题的 fact-seeking(事实寻求)提示时,通常会生成包含事实错误的内容。DeepMind 针对这一现象进行(Carry Out)了一些探索性研究。
首先,为了对一个模型在开放域的长篇事实性进行(Carry Out)基准测试,研究者使用 GPT-4 生成 LongFact,它是一个包含 38 个主题、数千个问题的提示集。然后他们(They)提出使用搜索增强事实评估器(Search-Augmented Factuality Evaluator, SAFE)来将 LLM 智能体用作长篇事实性的自动评估器。
对于 SAFE,它利用(Use) LLM 将长篇响应分解为一组单独的事实,并使用多步推理过程来评估每个事实的准确性。这里多步推理过程包括将搜索查询发送到 Google 搜索并确定搜索结果(Result)是否支持某个事实 。

论文地址:https://arxiv.org/pdf/2403.18802.pdf
GitHub 地址:https://github.com/google-deepmind/long-form-factuality
此外,研究者提出将 F1 分数(F1@K)扩展为长篇事实性的聚合指标。他们(They)平衡了响应中支持的事实的百分比(精度)和所提供事实相对于代表用户首选响应长度的超参数的百分比(召回率)。
实证结果(Result)表明,LLM 智能体可以达成超越人类的评级性能。在一组约 16k 个单独的事实上,SAFE 在 72% 的情况下与人类注释者一致,并且在 100 个分歧案例的随机子集上,SAFE 的赢率为 76%。同时,SAFE 的成本比人类注释者便宜 20 倍以上。
研究者还使用 LongFact,对四个大模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 种流行的语言模型进行(Carry Out)了基准测试,结果(Result)发现较大的语言模型通常可以达成更好的长篇事实性。
论文作者之一、谷歌研究科学家 Quoc V. Le 表示,这篇对长篇事实性进行(Carry Out)评估和基准测试的新工作提出了一个新数据集、 一种新评估方法以及一种兼顾精度和召回率的聚合指标。同时所有数据和代码将开源以供将来工作使用。
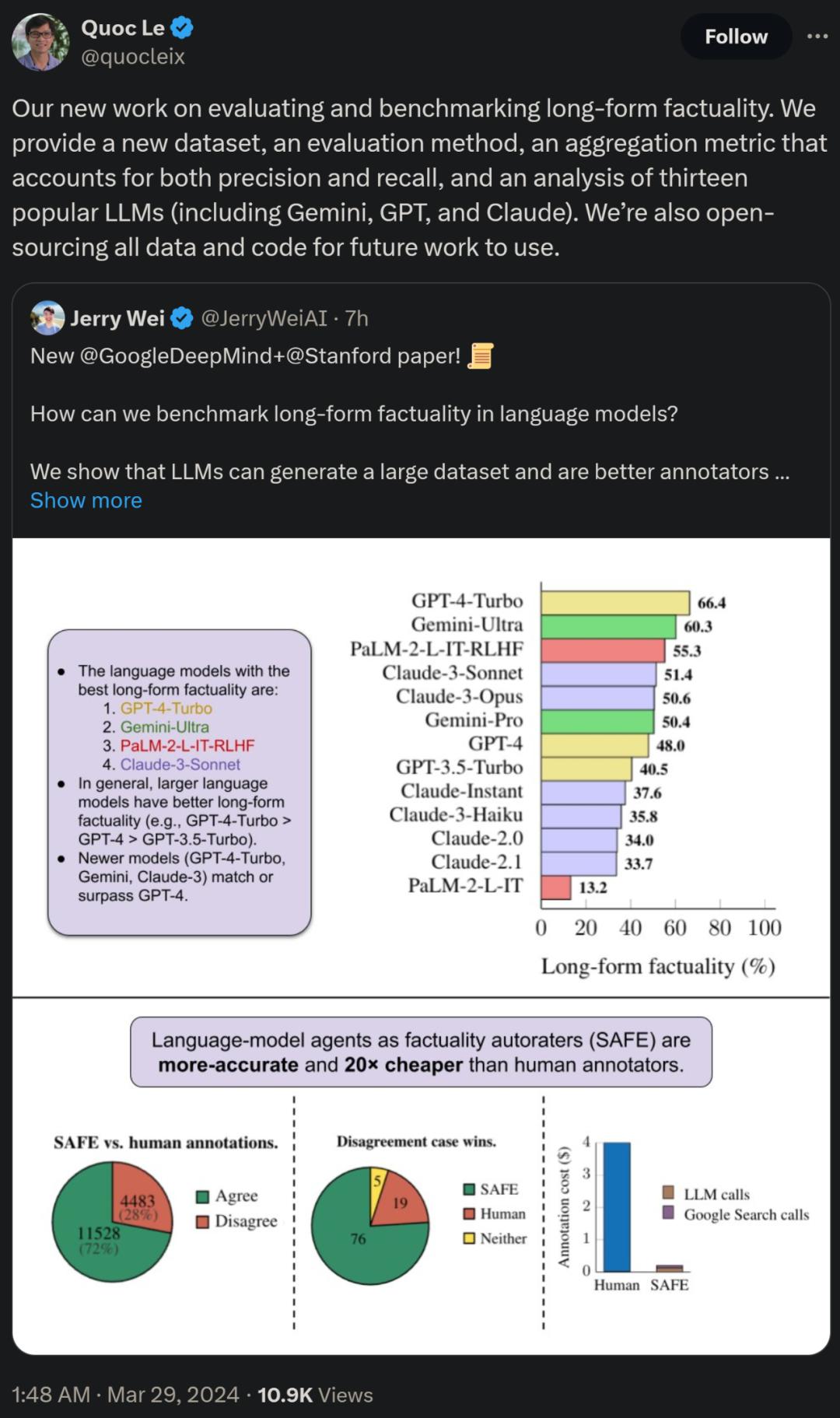
首先来看使用 GPT-4 生成的 LongFact 提示集,包含了 2280 个事实寻求提示,这些提示要求跨 38 个手动选择主题的长篇响应。研究者表示,LongFact 是第一个用于评估各个领域长篇事实性的提示集。
LongFact 包含两个任务:LongFact-Concepts 和 LongFact-Objects,根据问题是否询问概念可能对象来区分。研究者为每个主题生成 30 个独特的提示,每个任务各有 1140 个提示。

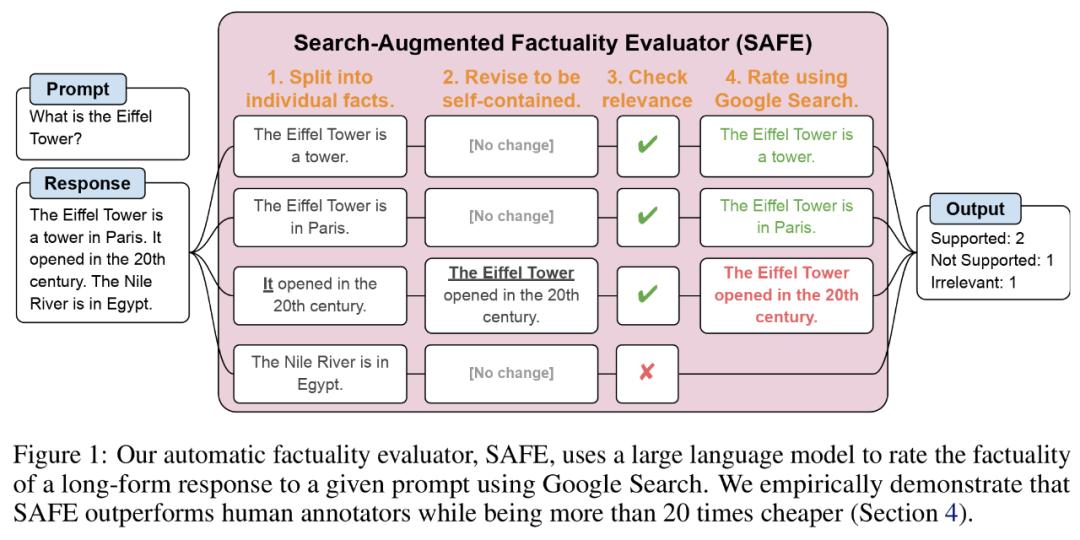
研究者提出了搜索增强事实评估器(SAFE),它的运行原理如下所示:
a)将长篇的响应拆分为单独的独立事实;
b)确定每个单独的事实是否与回答上下文中的提示相关;
c) 对于每个相关事实,在多步过程中迭代地发出 Google 搜索查询,并推理搜索结果(Result)是否支持该事实。
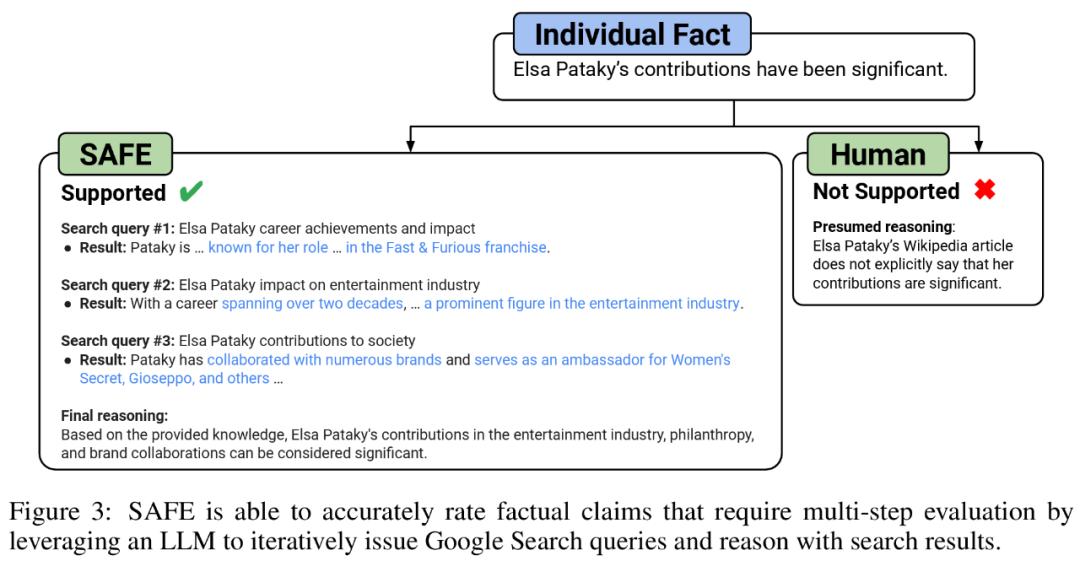
他们(They)认为 SAFE 的关键创新在于使用语言模型作为智能体,来生成多步 Google 搜索查询,并仔细推理搜索结果(Result)是否支持事实。下图 3 为推理链示例。
为了将长篇响应拆分为单独的独立事实,研究者首先提示语言模型将长篇响应中的每个句子拆分为单独的事实,然后通过指示模型将模糊引用(如代词)替换为它们(They)在响应上下文中引用的正确实体,将每个单独的事实修改为独立的。
为了对每个独立的事实进行(Carry Out)评分,他们(They)使用语言模型来推理该事实是否与在响应上下文中回答的提示相关,接着使用多步方法将每个剩余的相关事实评级为「支持」可能「不支持」。具体如下图 1 所示。
在每个步骤中,模型都会根据要评分的事实和之前获得的搜索结果(Result)来生成搜索查询。经过一定数量的步骤后,模型执行推理以确定搜索结果(Result)是否支持该事实,如上图 3 所示。在对所有事实进行(Carry Out)评级后,SAFE 针对给定提示 - 响应对的输出指标为 「支持」事实的数量、「不相关」事实的数量以及「不支持」事实的数量。
实验结果(Result)LLM 智能体成为比人类更好的事实注释者为了定量评估使用 SAFE 获得注释的质量,研究者使用了众包人类注释。这些数据包含 496 个提示 - 响应对,其中响应被手动拆分为单独的事实(总共 16011 个单独的事实),并且每个单独的事实都被手动标记为支持、不相关可能不支持。
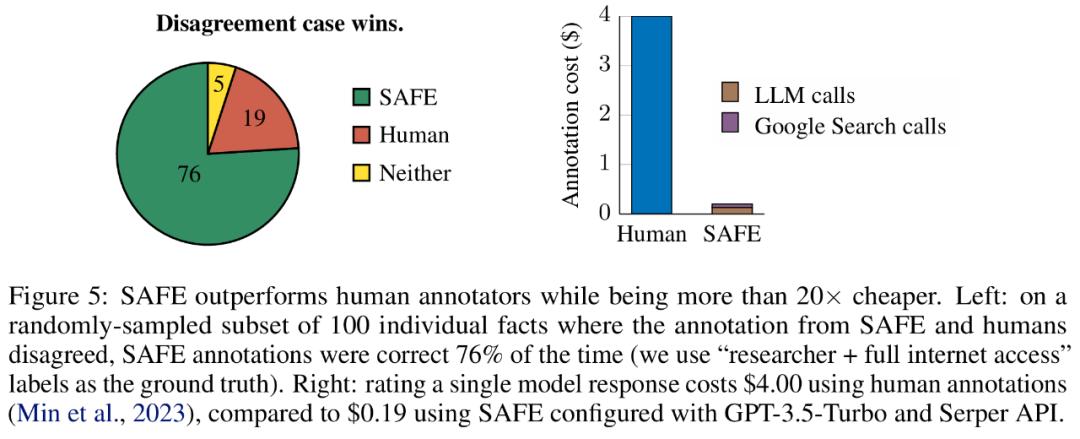
他们(They)直接比较每个事实的 SAFE 注释和人类注释,结果(Result)发现 SAFE 在 72.0% 的单独事实上与人类一致,如下图 4 所示。这表明 SAFE 在大多数单独事实上都达到了人类水平的表现。然后检查随机采访的 100 个单独事实的子集,其中 SAFE 的注释与人类评分者的注释不一致。

研究者手动重新注释每个事实(允许访问 Google 搜索,而不仅仅是维基百科,以获得更全面的注释),并使用这些标签作为基本事实。他们(They)发现,在这些分歧案例中,SAFE 注释的正确率为 76%,而人工注释的正确率仅为 19%,这代表 SAFE 的胜率是 4 比 1。具体如下图 5 所示。
这里,两种注释方案的价格非常值得关注。使用人工注释对单个模型响应进行(Carry Out)评级的成本为 4 美元,而使用 GPT-3.5-Turbo 和 Serper API 的 SAFE 仅为 0.19 美元。
最后,研究者在 LongFact 上对下表 1 中四个模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 个大语言模型进行(Carry Out)了广泛的基准测试。
具体来讲,他们(They)利用(Use)了 LongFact-Objects 中 250 个提示组成的相同随机子集来评估每个模型,然后使用 SAFE 获取每个模型响应的原始评估指标,并利用(Use) F1@K 指标进行(Carry Out)聚合。

结果(Result)发现,一般而言,较大的语言模型可以达成更好的长篇事实性。如下图 6 和下表 2 所示,GPT-4-Turbo 优于 GPT-4,GPT-4 优于 GPT-3.5-Turbo,Gemini-Ultra 优于 Gemini-Pro,PaLM-2-L-IT-RLHF 优于 PaLM- 2-L-IT。

更多技术细节和实验结果(Result)请参阅原论文。
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:关注大模型的,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
+10好文章,需要你的鼓励
机器之心特邀作者0收 藏+10评 论打开微信“扫一扫”,打开网页后点击屏幕右上角分享按钮微 博沉浸阅读返回顶部参与评论评论千万条,友善第一条登录后参与讨论(Discuss)提交评论0/1000你可能也喜欢这些文章你正在看的短视频(Short Video),文案翻译出镜剪辑全都是AI“双面”AIGC:变脸、界线与博弈最强开源大模型再度易主,这家初创公司是如何做到的?马斯克大模型Grok1.5来了:推理能力大升级,支持128k上下文AI影响祖国集成电路的几点思考Mamba超强进化体一举颠覆Transforme,单张A100跑140K上下文这一年,AI开始改变商业向善的尺度AI国力战争:GPU是明线,HBM是暗线8 名谷歌员工发明了现代人工智能,这是那篇论文的内幕故事最新文章推荐抖音(Tik Tok)电商,推出了自己的“淘宝”分身一只手镯便宜2400元,你会去银行买金首饰吗?欢迎小米来到“刺激战场”4500万成本撬动33亿销售额,微短剧成美妆品牌带货利器李斌直播带货BaaS,蔚来出圈你正在看的短视频(Short Video),文案翻译出镜剪辑全都是AI给祖国创始人的全球化指南:水平地切开世界雷军“交卷”:小米汽车(Car)没敢冒险雷军临门降价引爆小米SU7,一夜卖光一年产能,高管自曝回工厂007“双面”AIGC:变脸、界线与博弈 机器之心特邀作者
机器之心特邀作者专业的人工智能媒体和产业服务平台
发表文章489篇最近内容DeepMind终结大模型幻觉?标注事实比人类靠谱、还便宜20倍,全开源1小时前马斯克大模型Grok1.5来了:推理能力大升级,支持128k上下文1小时前词曲创作只需几秒,「AI作曲家」Suno引爆音乐(Music)圈,第一手体验和攻略来了2024-03-25阅读更多内容,狠戳这里下一篇马斯克大模型Grok1.5来了:推理能力大升级,支持128k上下文即将在 X 平台中上线。
1小时前
热门标签成都货运微信拍卖艺术品电商陶金多校划片西城学区划片存量土地国人的名义北平无战事琅琊榜吸血鬼日记潜伏素食芈月传生意经潮牌橱窗堡垒之夜网贷银行存管协会汇率欧元固定汇率广州酒家月饼西府海棠茂业紫光控方证人狗刚需关于36氪城市合作寻求报道我要入驻投资者关系商务合作关于我们(We)联系我们(We)加入我们(We)网站谣言信息举报入口热门推荐热门资讯热门产品文章标签快讯标签合作伙伴






 36氪APP下载
36氪APP下载 iOS Android
iOS Android 本站由 阿里云 提供计算与安危服务 违法和不良信息、未成年人保护举报电话:010-89650707 举报邮箱:jubao@36kr.com 网上有害信息举报© 2011~2024 首都多氪信息科技(Technology)有限公司 | 京ICP备12031756号-6 | 京ICP证150143号 | 京公网安备11010502036099号意见反馈36氪APP让一部分人先看到将来36氪鲸准氪空间
本站由 阿里云 提供计算与安危服务 违法和不良信息、未成年人保护举报电话:010-89650707 举报邮箱:jubao@36kr.com 网上有害信息举报© 2011~2024 首都多氪信息科技(Technology)有限公司 | 京ICP备12031756号-6 | 京ICP证150143号 | 京公网安备11010502036099号意见反馈36氪APP让一部分人先看到将来36氪鲸准氪空间
推送和解读前沿、有料的科技(Technology)创投资讯

一级市场金融信息和系统服务提供商

聚焦全球优秀创业者,项目融资率接近97%,领跑行业
相关文章








- 赞(439) 踩(56) 阅读数(6182) 最新评论 查看所有评论
-
加载中......
- 发表评论
-